Foundation foods#
Changed in version v2.1.0: This functionality matches ingredients to the FDC database.
Whilst the changes are API compatible with earlier versions, the contents of the fields in the FoundationFood objects are different.
The goal of the foundation foods functionality is to match the ingredient names identified from the ingredient sentence to entries in the USDA’s Food Data Central (FDC) database.
The foundation_foods optional keyword argument for the parse_ingredient function enables this functionality when set to True.
For example, in the sentence
24 fresh basil leaves or dried basil
the parse_ingredient function will identify two names: fresh basil leaves and dried basil. The matching FDC entries are Basil, fresh and Spices, basil, dried.
>>> from ingredient_parser import parse_ingredient
>>> parse_ingredient("24 fresh basil leaves or dried basil", foundation_foods=True)
ParsedIngredient(
name=[IngredientText(text='fresh basil leaves',
confidence=0.973058,
starting_index=1),
IngredientText(text='dried basil',
confidence=0.87027,
starting_index=5)],
size=None,
amount=[IngredientAmount(quantity=Fraction(24, 1),
quantity_max=Fraction(24, 1),
unit='',
text='24',
confidence=0.999702,
starting_index=0,
unit_system=<UnitSystem.NONE: 'none'>,
APPROXIMATE=False,
SINGULAR=False,
RANGE=False,
MULTIPLIER=False,
PREPARED_INGREDIENT=False)],
preparation=None,
comment=None,
purpose=None,
foundation_foods=[FoundationFood(text='Basil, fresh',
confidence=0.862222,
fdc_id=172232,
category='Spices and Herbs',
data_type='sr_legacy_food',
url='https://fdc.nal.usda.gov/food-details/172232/nutrients'),
FoundationFood(text='Spices, basil, dried',
confidence=0.856791,
fdc_id=171317,
category='Spices and Herbs',
data_type='sr_legacy_food',
url='https://fdc.nal.usda.gov/food-details/171317/nutrients')],
sentence='24 fresh basil leaves or dried basil'
)
This functionality works entirely offline. A subset of the full download of the FDC database is distributed with this library, which includes the foudation_food, sr_legacy_food and survey_fndds_food data sets. This data is used when matching an ingredient name to an FDC entry.
Caution
Enabling this functionality is much slower than when not enabled. When enabled, parsing a sentence is roughly 20x slower than if disabled, but the actual slow down depends on the sentence.
Explanation#
The matching of the ingredient names to entries in the FDC database is a difficult problem. The descriptions of the entries in the FDC database are quite different to the way the ingredients are commonly referred to in recipes, therefore matching one to the other is a challenge. For example, the matching entry for spring onions has a description of Onions, spring or scallions (includes tops and bulb), raw.
Therefore a number of search engine ranking functions are used, and the results fused together to obtain the best (and hopefully most relevant) result. The different search engine ranking function have different characteristics:
BM25 [1] considers exact matching tokens, and weights tokens according the relevance of the information each token conveys.
uSIF [2] is a semantic ranking function that uses GloVe embeddings to rank FDC ingredients based semantic similarity.
Fuzzy [4] is an alternative approach to semantic ranking, also use the GloVe embeddings.
For the semantic raking functions, a GloVe embeddings model trained on text from a large corpus of recipes is used to provide the information for the semantic similarity techniques.
Important
The semantic ranking function can only be used where the ingredient name contains tokens that are in the embeddings model. Where the ingredient name does not contain any tokens in the embeddings model, only BM25 is used.
The flow chart below outlines the process of matching an FDC ingredient to an ingredient name.
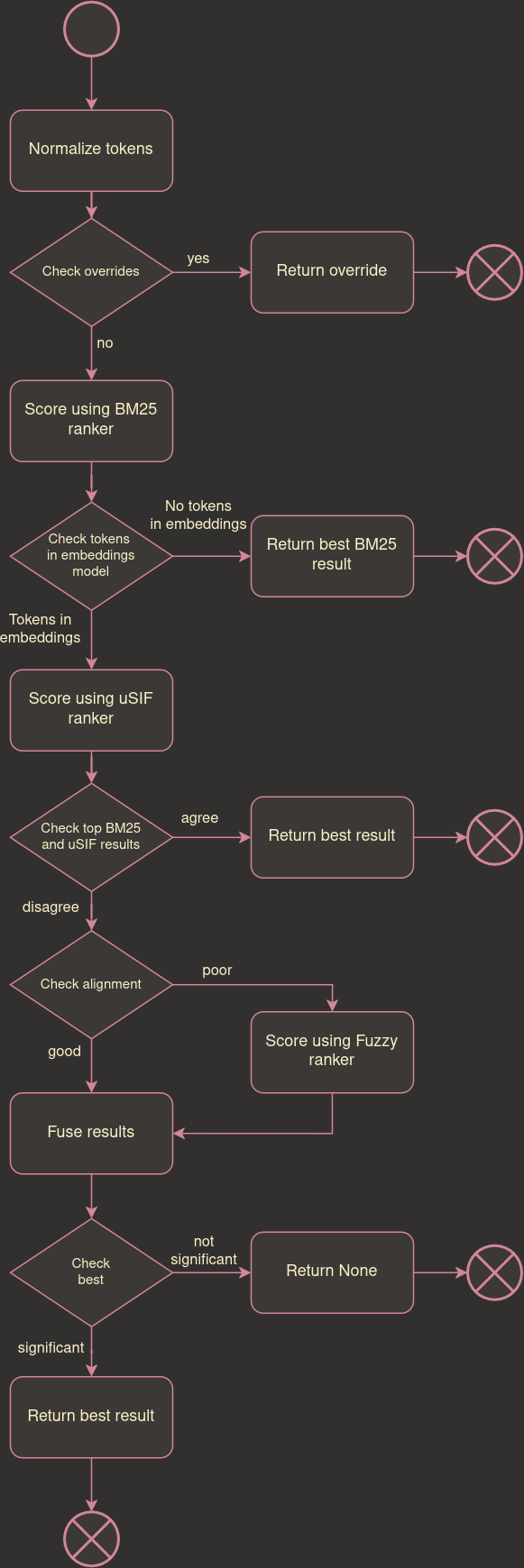
Foundation food matching process.#
1. Normalize tokens#
The ingredient name tokens are normalized by taking the following steps:
Splitting tokens containing hyphens into separate tokens.
Discarding tokens that are numbers, white space or only a single character.
Stemming the remaining tokens.
Discarding tokens that are not in the embeddings model.
In addition, any ambiguous adjectives that occur at the start of the ingredient name are removed. Ambiguous adjectives are those that have multiple meaning which can cause confusion in the subsequent scoring steps. For example, hot can refer to temperature or spiciness. It is removed to prevent ingredients with a hot temperature being confusing with FDC entries that are spicy.
Note
The same normalization process is also applied to the FDC entry descriptions.
Additional tokens may be added to the ingredient name at this point to help bias the results towards more relevant FDC entries.
For example, most FDC entries explicitly state if the item is raw, however ingredient sentences commonly do not.
If the ingredient name does not contain any tokens that indicate it is not raw, the token raw is added to the name.
2. Check overrides#
The foundation food matching process can sometimes struggle with simple ingredient names because the relevant FDC entry often do not have a simple description.
A list of overrides that map simple of ingredient names to the relevant FDC entry is used to ensure a correct match for these cases.
3. Rank using BM25 matcher#
A ranking technique called Best Matching 25 [1] is used rank the FDC entries in order of relevance. This technique calculates a similarity score between a query and a document and uses the term frequency and inverse document frequency to estimate the relative importance of each token.
This approach is generally very effective, however it relies on the same words used in the ingredient name and FDC description. Since this is not always the case, we can combine it with the uSIF ranker to handle cases where different words are used to refer to the same ingredient.
>>> from ingredient_parser.en.foundationfoods._bm25 import get_bm25_ranker
>>> BM25 = get_bm25_ranker()
>>> rankings = BM25.rank_matches(["red", "pepper"])
>>> for rank in rankings[:5]:
print(f"{rank.score:.4f}: {rank.fdc.description}")
14.4585: Peppers, sweet, red, raw
14.4585: Peppers, bell, red, raw
13.3526: Peppers, hot chili, red, raw
12.9365: Peppers, red, cooked
11.8650: Peppers, sweet, red, sauteed
To avoid BM25 ranking FDC entries highly where they do not truly match the ingredient name, FDC entries that do not share a common token with the nouns in the ingredient name are filtered out from the rankings.
Hint
The scores produced by BM25 have an arbitrary value, where a bigger number means more similar. This means that scores cannot be compared between different sets of rankings, only the relative values within a ranking are meaningful.
4. Rank using uSIF matcher#
A semantic ranking technique called Unsupervised Smooth Inverse Frequency (uSIF) [2] is used to rank the FDC entries in order of relevance. This technique calculates an embedding vector for a sentence from the weighted vectors of the words, where the weight is proportional to the probability of encountering the word (related to the inverse frequency of the word). This is done for each FDC entry and the ingredient name, and cosine similarity is used to rank the FDC entries according to best matching.
Note
The technique described in [2] also removes common components in the word vectors. This is not implemented here (primarily due to not wanting to include a further runtime dependency of sklearn - this may change in the future if it proves to be helpful).
In practice, this technique is generally pretty good at finding a reasonable matching FDC entry. However, in some cases the match with the best score is not an appropriate match. The reason for this is likely due to limitations in the quality of the embeddings used.
This approach has been extended to introduce additional token weights for the FDC entries based on the phrase position in the description. These weights are specific to each FDC entry and are based on the following
The phrase position: the further the phrase is from the start of the description, the less relevant it is.
Negative tokens: tokens within a phrase that follow a negative token (e.g. no, without) are given a weight of 0 so they are ignored.
This helps avoid confusion where the presence of a token in the sentence results in a similar vector despite being used in a negative context.
Reduced relevance tokens: tokens within a phrase that follow a token indicating reduced relevance have their weight reduced.
As an example, in the description Chicken, canned, with broth, the token with indicates the following tokens (i.e. broth) are less relevant to the ingredient the description is for.
>>> from ingredient_parser.en.foundationfoods._usif import get_usif_ranker
>>> usif = get_usif_ranker()
>>> rankings = usif.rank_matches(["red", "pepper"])
>>> for rank in rankings[:5]:
print(f"{rank.score:.4f}: {rank.fdc.description}")
0.0840: Peppers, bell, red, raw
0.0870: Peppers, sweet, red, raw
0.1079: Peppers, red, cooked
0.1096: Peppers, sweet, green, raw
0.1113: Onions, red, raw
Tip
The difference between the BM25 ranker can be seen in the example here.
BM25 gives the first two result equal scores because neither bell nor sweet were specified, where the uSIF ranker ranked Peppers, bell, red, raw higher because the embeddings showed a higher similarity with the ingredient name.
Hint
uSIF uses cosine similarity for scoring. Each score is a value between 0 and 1, where a smaller number means more similar.
5. Check for agreement of best result#
To avoid the further computation of the score fusion (and potentially another ranking technique), the top result from the BM25 and uSIF rankers are checked to see if they are the same. If they are the same, then that top result is returned and the remaining processing is skipped.
Tip
When we check the agreement of the top results, we need to consider that each ranker may have more than result with the same score as the top score. This is particularly likely for the BM25 ranker, as seen above.
6. Check uSIF and BM25 alignment#
The fuzzy document distance technique described below is another semantic ranking technique, but it has the downside of being significantly more computationally expensive and therefore slow than the uSIF and BM25 techniques.
To avoid always having this slow down, the decision of when to use this is based on how well aligned the results from the uSIF and BM25 matchers are. If uSIF and BM25 produce well aligned results (that is, a similar set of FDC entries ranked in a similar order), then we do not need to use the fuzzy document distance technique. If the uSIF and BM25 results are not well aligned, then we will use the fuzzy document distance technique on the union of the top results from each matcher to provide another source of rankings for the results fusion later.
The alignment of the uSIF and BM25 results is quantified using rank-biased overlap ([3]). This calculates a score between 1 (identical rankings) and 0 (disjoint rankings). A score below the set threshold triggers the use of the fuzzy document distance ranker.
7. Score using Fuzzy ranker#
The fuzzy document distance metric is described in [4] and is also used rank the FDC entries in order of relevance. Each sentence is considered as an unordered set of tokens, and the distance is calculated from the Euclidean distance between tokens in two sentences being compared. By considering the embedding vector for each token individually, this technique can yield different results to uSIF but is quite effective nonetheless.
The results using this approach are easier to reason about than the result from uSIF, however the implementation of this metric has the downside of being significantly slower.
>>> from ingredient_parser.en.foundationfoods._fuzzy import get_fuzzy_ranker
>>> fuzzy = get_fuzzy_ranker()
>>> rankings = fuzzy.rank_matches(["red", "pepper"])
>>> for rank in rankings[:5]:
print(f"{rank.score:.4f}: {rank.fdc.description}")
0.0998: Peppers, bell, red, raw
0.1002: Peppers, sweet, red, raw
0.1687: Peppers, hot chili, red, raw
0.1848: Onions, red, raw
0.2068: Peppers, jalapeno, raw
Hint
Each score for the fuzzy document distance is a value between 0 and 1, where a smaller number means more similar.
8. Fuse results#
To obtain the best matching FDC entry, the rankings from the two (or three) ranking techniques are fused together using Distribution-Based Score Fusion [5]. This fusion algorithm considers both the ranking of each FDC entry and it’s normalised score to determine an overall ranking.
This technique has been extended to also consider the confidence of each ranking technique used. Ranker confidence can be estimated in two ways:
The relative gap between the scores of two highest ranked items: a larger gap indicates higher confidence.
The variance in the non-top scores: a smaller variance indicates higher confidence.
Both of these methods are considered and used to estimate a relative confidence for each ranker, which is used to influence the DBSF result.
From an efficient implementation perspective, only the top 100 results are considered. This helps avoid the really poorly matching FDC entries affecting the score distribution statistics (because every FDC entry gets a score even if the match is terrible).
>>> fused_rankings = fuse_results(bm25_matches, fuzzy_matches, usif_matches, top_n=100)
# Ranker confidences: BM25=1.2587, uSIF=1.7413, Fuzzy=0.0000
>>> for rank in fused_rankings[:5]:
print(f"{rank.score:.4f}: {rank.fdc.description}")
1.0000: Peppers, bell, red, raw
0.9914: Peppers, sweet, red, raw
0.8617: Peppers, red, cooked
0.7392: Peppers, hot chili, red, raw
0.6994: Peppers, sweet, red, sauteed
Hint
Note how the uSIF ranker is given higher confidence than BM25. This is because the BM25 ranker gave the same score to the top two results, where the uSIF ranker did not.
In the example, because the uSIF and BM25 rankers had good alignment, the fuzzy document distance ranker was not used (and therefore has a confidence of 0).
9. Check if the best result is significant#
To avoid return an FDC entry that is in reality a poor match but the processing described considers a good match, the significance of the confidence is checked. If the confidence of the best match is < 0.95 and there is less than a 1% difference in confidence score between the best and second best match, the best match is considered not significant enough and no matching FDC entry is returned.
Warning
This significance heuristic is based on manual testing and is unlikely to be perfect. Improvements will made in future releases.