Model Usage#
With a model trained, it can be used to label the tokens of an ingredient sentence. The process is shown in the figure below, taking the lower Parsing branch of the diagram.
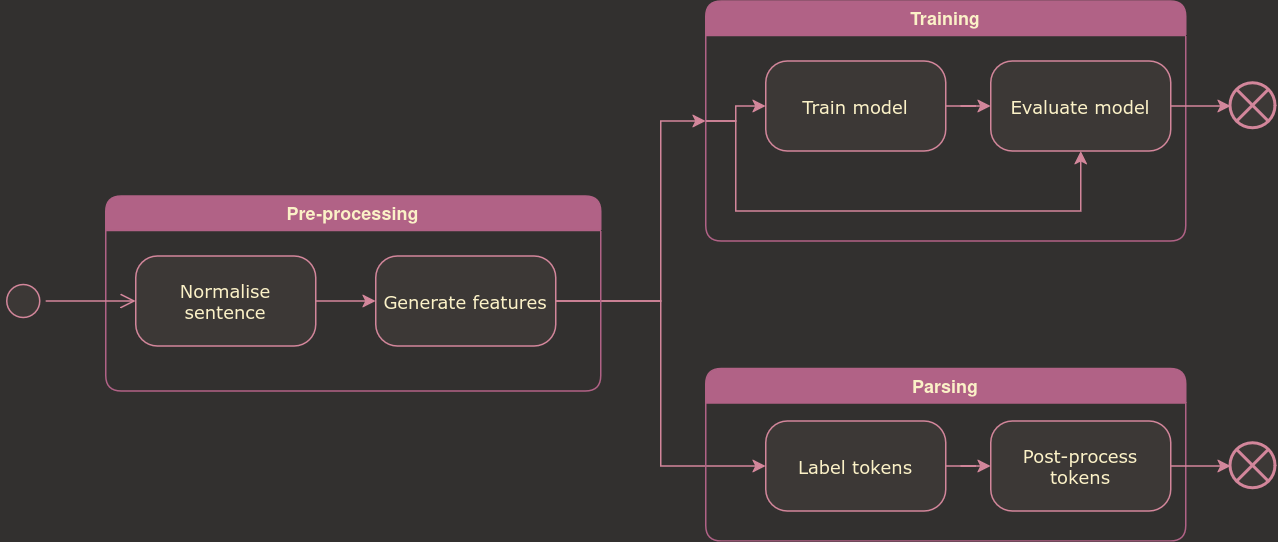
Training and parsing pipelines.#
The (simplified) code looks like
>>> from ingredient_parser.en import PreProcessor
>>> import pycrfsuite
# Pre-process sentence
>>> p = PreProcessor("100 g green beans")
# Create tagger object and load model
>>> tagger = pycrfsuite.Tagger()
>>> tagger.open("model.en.crfsuite")
# Predict labels using token features
>>> labels_pred = tagger.tag(p.sentence_features())
tagger.tag(...) returns a list of labels the same length as the list of sentence features.
For example, consider the sentence 3/4 cup (170g) heavy cream:
>>> p = PreProcessor("3/4 cup (170g) heavy cream")
>>> [t.text for t in p.tokenized_sentence]
['#3$4', 'cup', '(', '170', 'g', ')', 'heavy', 'cream']
>>> tagger.tag(p.sentence_features())
['QTY', 'UNIT', 'PUNC', 'QTY', 'UNIT', 'PUNC', 'B_NAME_TOK', 'I_NAME_TOK']
The confidence score can be calculated for each label too
>>> [tagger.marginal(label, i) for i, label in enumerate(labels)]
[0.99969..., 0.9991524..., 0.997019..., 0.907705..., 0.910985..., 0.962122..., 0.998440..., 0.996780...]
The confidence score is a value between 0 and 1 which represents the model’s belief that a given label is correct. The sum of the scores for all possible labels for a given token is equal to 1.