Model Guide#
The core functionality of this library is provided by a sequence tagging natural language model.
The model takes a sequence of features calculated from the input sentence and assigns a label to each element of the sequence.
Post-processing of the sequence of labels and tokens is then used to populate the ParsedIngredient object.
The figure below shows the processing pipelines used for training the model and parsing a sentence.
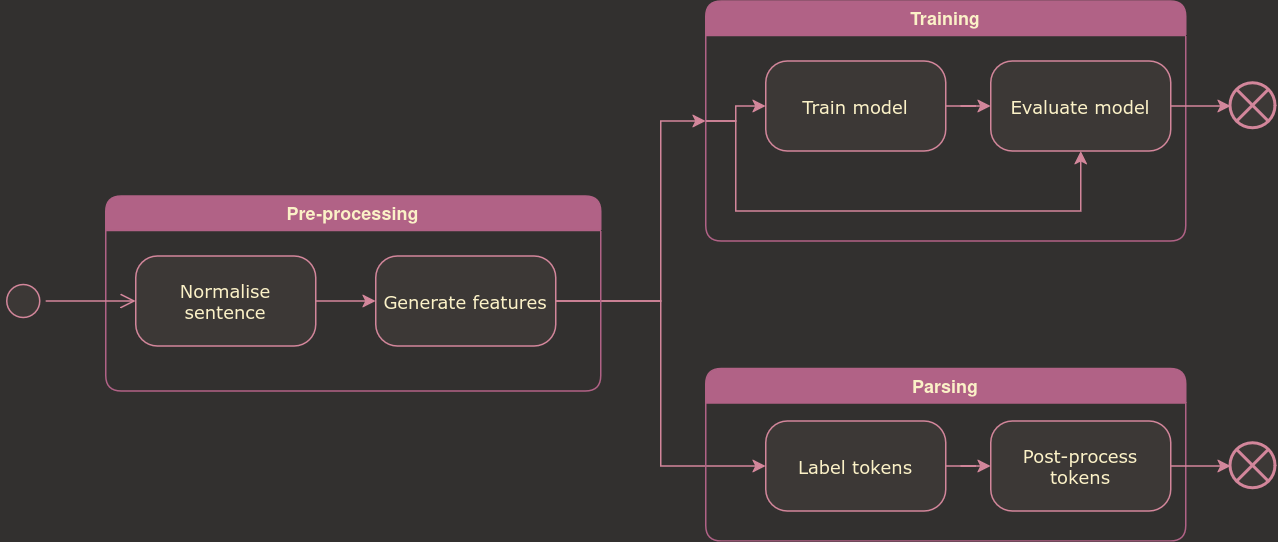
Training and parsing pipelines.#
The first step is normalising the input sentence. The goal of normalisation is to transform certain aspects of the sentence into a standardised form to make it easier for the model to learn the correct labels, and make subsequent post-processing easier too. The Sentence Normalisation page provides more details on this process.
The second step is feature generation. This is the process of splitting the sentence into tokens. For each token, a set of features are generated which can be based on the token itself or the surrounding tokens. The Feature Generation page provides more details on this process.
Training#
If we are training the model the third step is training. Here we take a large number of example sentences for which we know the correct label sequence and use them to train the model. Once a model has been trained, the fourth step is to evaluate it using example sentences we did not train the model on and that we also know the correct label sequence for.
The Data page provides details on the training data.
The Training page provides details on the model architecture, and training and evaluation steps.
Parsing#
If we are parsing a sentence, the third step is to use the model to label the tokens in the sentence. The Model Usage page provides more details on this process.
Once the sentence tokens have been labelled, the fourth step is to post-process the tokens and labels. The goal of the post-processing is to interpret the sequence of tokens and sequence of labels to determine the different parts of the sentence. In some cases, this is quite straightforward: just group token with the same label. In other cases, we look for particular patterns of tokens and labels to determine the output. The Post-processing page provides more details on this process.